|
|
||||||||||||||||||||||||||||||||||||
|
The Chinese University of Hong Kong, Shenzhen |
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
Sing voice conversion (SVC) is to convert singing voice to our desired targets. There are three common SVC tasks: Here are some examples: |
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
Source:
Target:
Jiawei Li. Use more chest resonance for increasing your singing’s power. Bilibili, 2022. |
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
Source:
Reference:
Target (source singer's content + reference singer's timbre):
|
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
Source (singing voice):
Reference (speech):
Target (source singer's content + reference speaker's timbre):
|
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
Impression Show to various singers:
|
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
| Tone Tuning: | ||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
Vocal music teaching:
|
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
| Translate vocal music to instrumental music: | ||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
| Here I listed some SVC papers with non-parallel data. "Non-parallel" means that we do not have the (source audio, target audio) pairs data. You can refer to this review to know more about it. | ||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
✍ Notes In this tutorial, the provided WORLD-based SVC baseline is classic. To know more about the contemporary SVC (such as using a neural vocoder and a stronger conversion model), you can refer to my latest work. |
||||||||||||||||||||||||||||||||||||
| All the source code of this baseline can be seen here. | ||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
WORLD [1] is a classical vocoder in Digital Signal Processing (DSP). It supposes there are three acoustic components of an audio: Fundamental frequency (F0), Spectral envelope (SP), and Aperiodic parameter (AP). It can be considered not only an extractor, which can extract F0, SP, and AP efficiently, but also a synthesizer, which can synthesis an audio by incorporating the three. Compared to the recent neural-based vocoders (such as WaveNet, WaveRNN, Hifi-GAN, Diffwave, etc.), WORLD is more like a white box and is more controllable and manipulable, while its synthesis quality is worse. We can easily adjust the input parameters to change the synthesized audios. For example, given such a male singing voice:
We can keep the F0 unchanged, and convert it to a robot-like voice:
Or, we can also increase the F0 two times, divide the SP by 1.2, and convert it to a female-like voice:
The official code of WORLD has been released here. You can play it, and manipulate the voice as you like! |
||||||||||||||||||||||||||||||||||||
| [1] Masanori Morise, et al. WORLD: A Vocoder-Based High-Quality Speech Synthesis System for Real-Time Applications. IEICE Trans. Inf. Syst. 2016. | ||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||
|
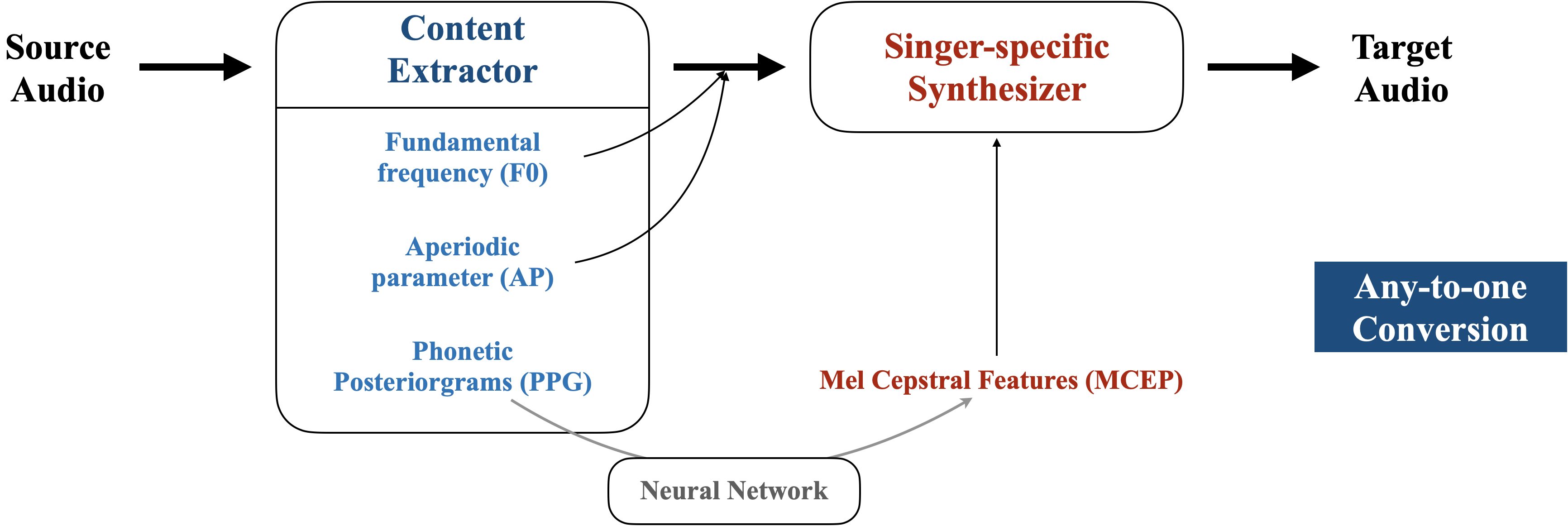
The conversion framework of the figure above is proposed by [1]. There are two main modules of it, Content Extractor and Singer-specific Synthesizer. Given a source audio, firstly the Content Extractor is aim to extract content features (i.e., singer independent features) from the audio. Then, the Singer-specific Synthesizer is designed to inject the singer dependent features for the synthesis, so that the target audio can be able to capture the singer's characteristics. The authors of [1] assume that among the three components of WORLD (i.e., F0, AP, and SP), only SP is singer dependent and should be modeled by the Singer-specific Synthesizer, while the other two can be considered pure content features. Based on that, we can utilize the following two stages to conduct any-to-one conversion: [1] Xin Chen, et al. Singing Voice Conversion with Non-parallel Data. IEEE MIPR 2019. |
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
The experiment setting is many-to-one conversion. Specifically, we consider Opencpop (which is a single singer dataset) as target singer and use M4Singer (which is a 19-singer dataset) as source singers. We adopt a python wrapper of WORLD to extract F0, AP, and SP, and to synthesis audios. We use diffsptk to transform between SP and MCEP. We utilize the last layer encoder's output of Whisper as the content features (which is 1024d). During training stage, we use a 6-layer Transformer to train the mapping from whisper features to 40d MCEP features. |
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
| Target Singer Samples (Opencpop): | ||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
| Conversion Samples (Convert different singers of M4Singer to Opencpop): | ||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
Cited as
Or
|