Improvements of Fine-tuning Vocoder with Singing Voice Data
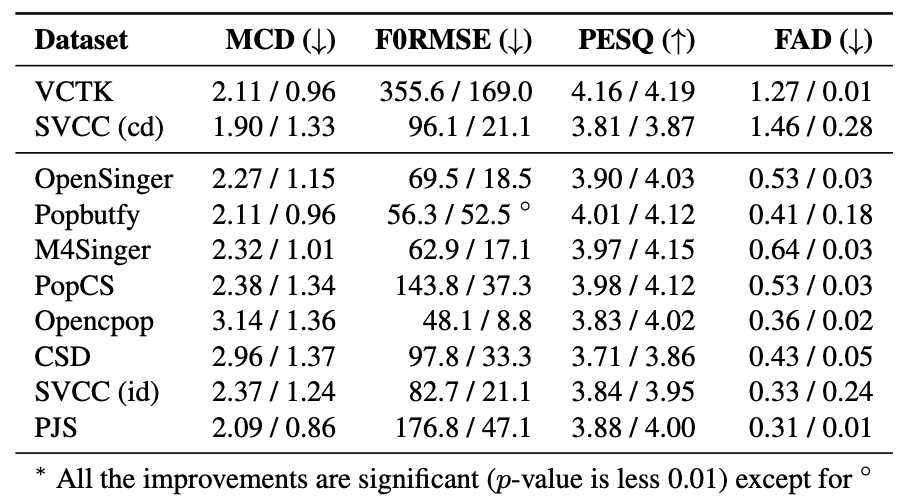
Table: Improvements after fine-tuning a pretrained speech vocoder by singing voice data.
The “before/after” means the results before and after fine-tuning.
After fine-tuning a pretrained BigVGAN vocoder (that is trained by 585 hours LibriTTS) with singing voice data, we find that the fine-tuned one is improved among spectrogram reconstruction (MCD), pitch modeling (F0RMSE), and perceptual audio quality (PESQ, FAD).
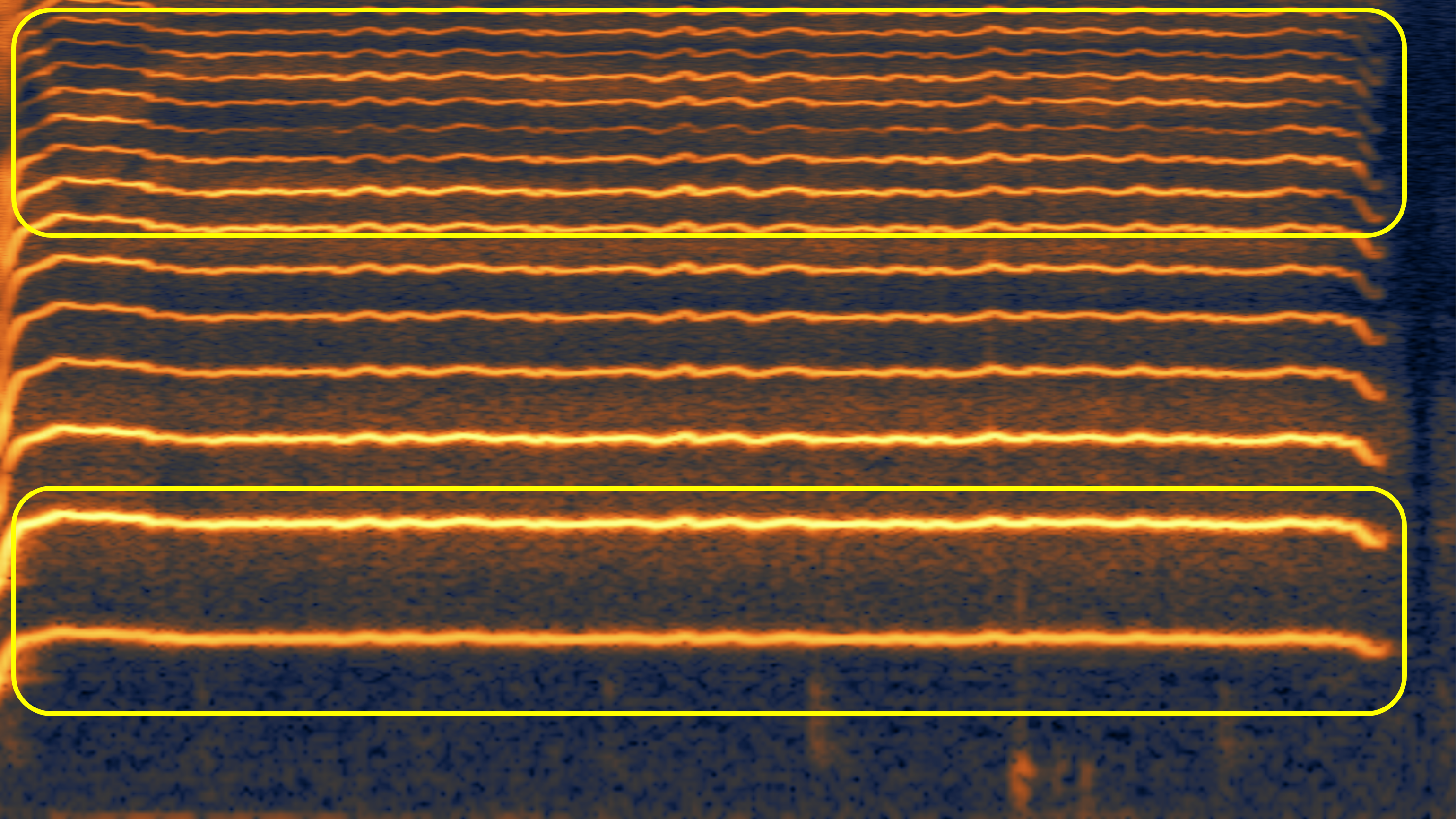
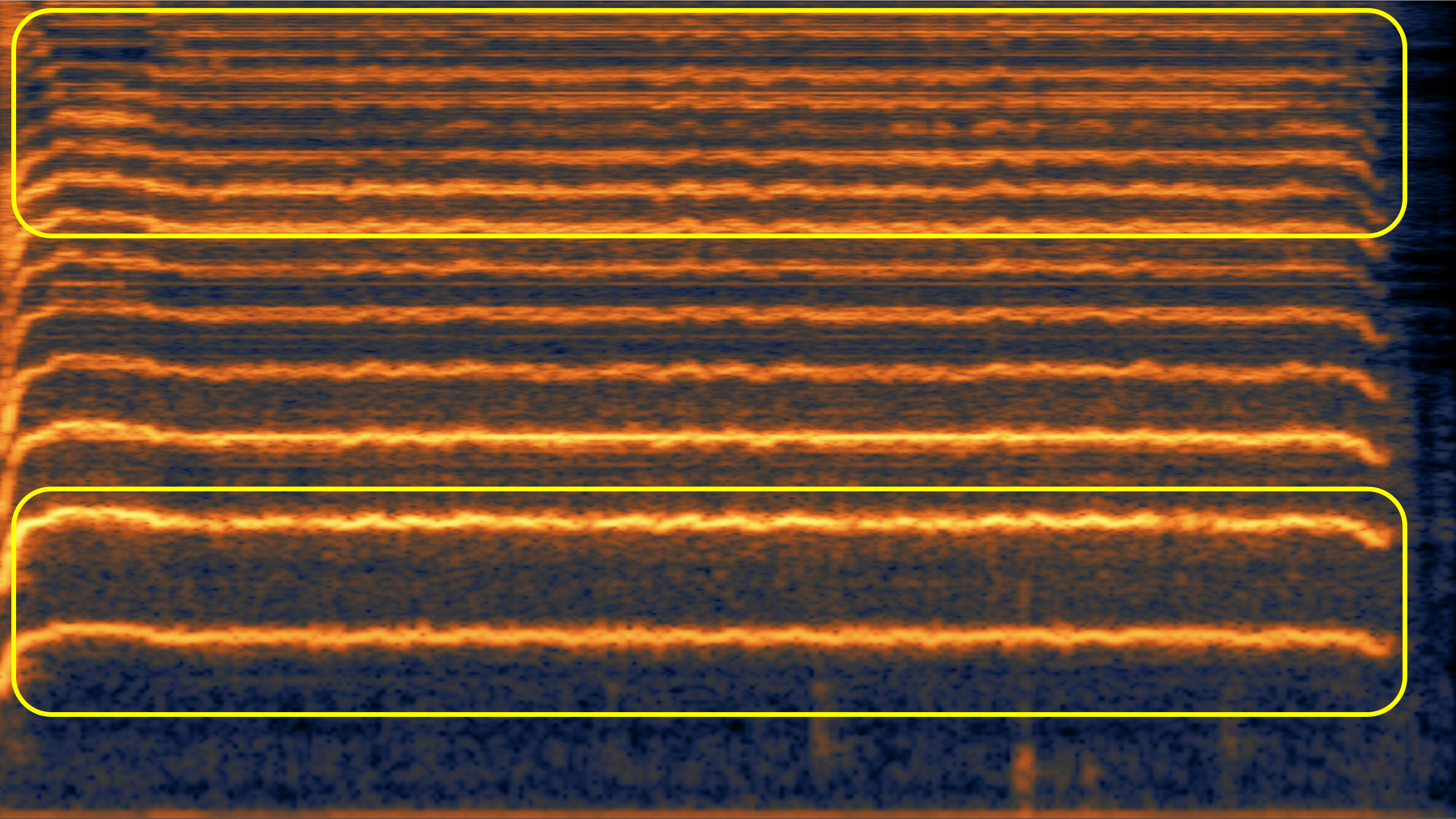
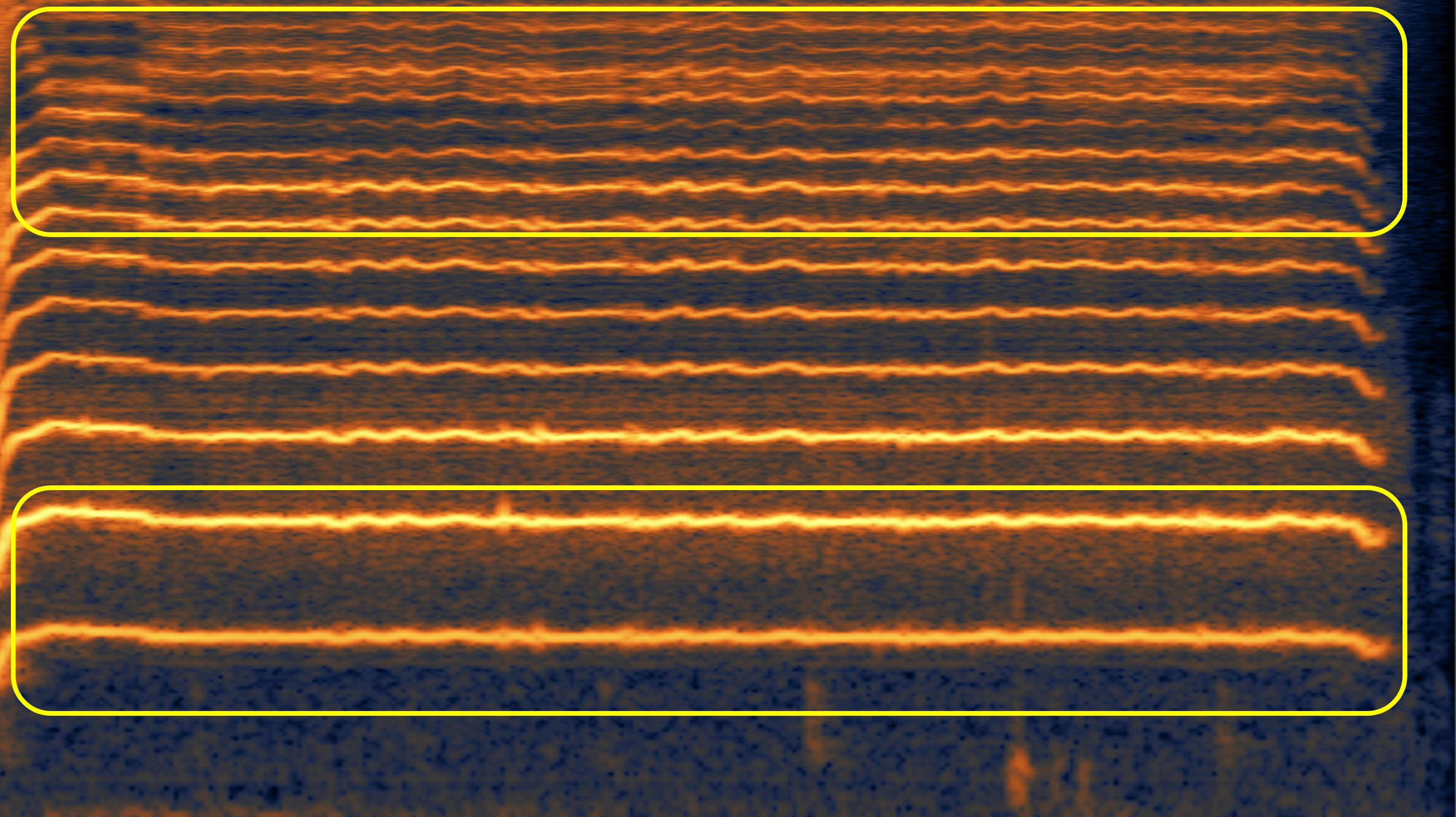
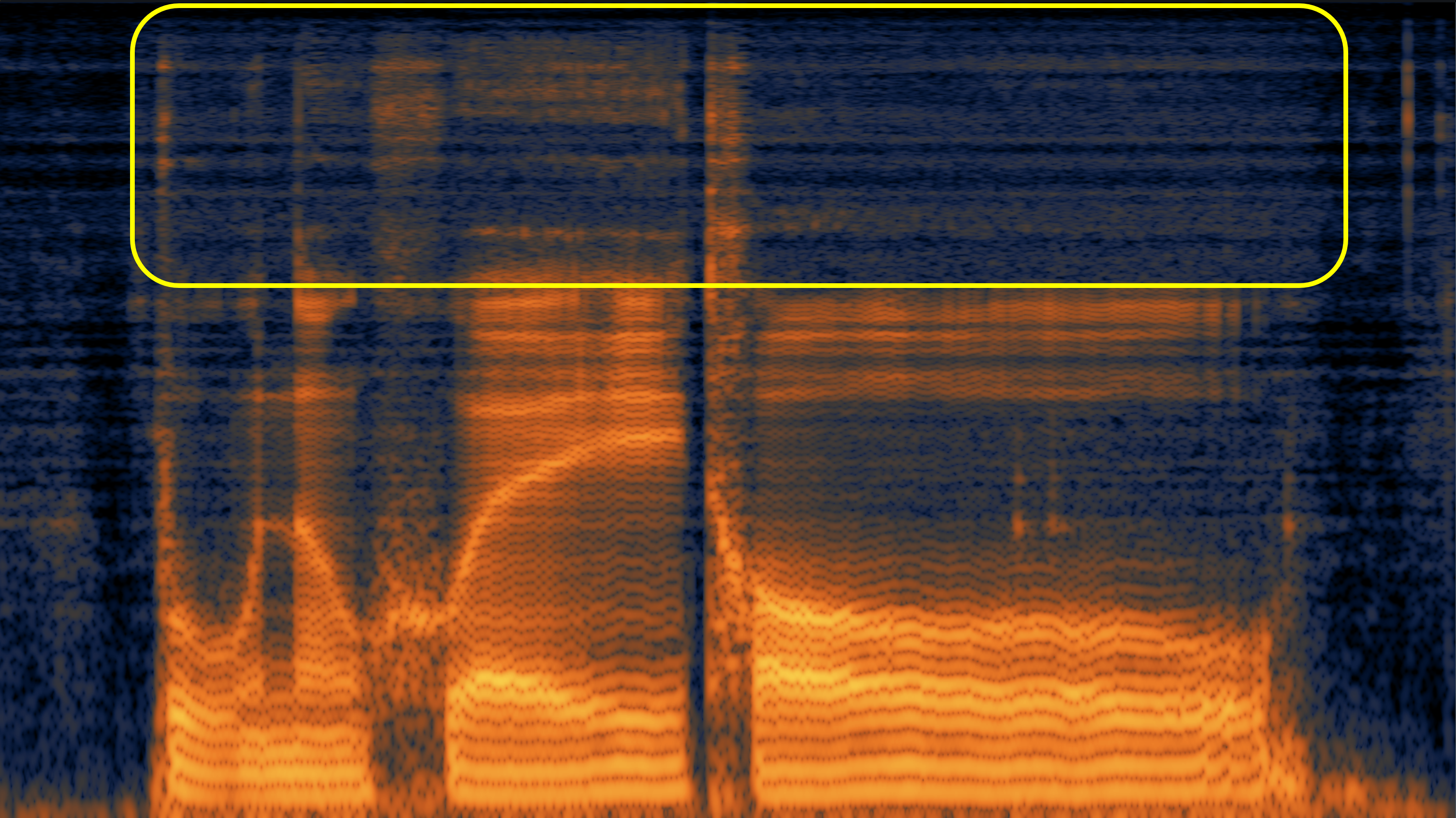
Here, we aim to show the weaknesses of the original speech vocoder (such as the "glitches" in case 1, and poor high-frequency reconstruction in case 2 and 3), and how much the fine-tuning can alleviate them.
| Ground Truth | Before Fine-tuning | After Fine-tuning | |
|---|---|---|---|
| #1 | |||
|
|
|
|
| #2 | |||
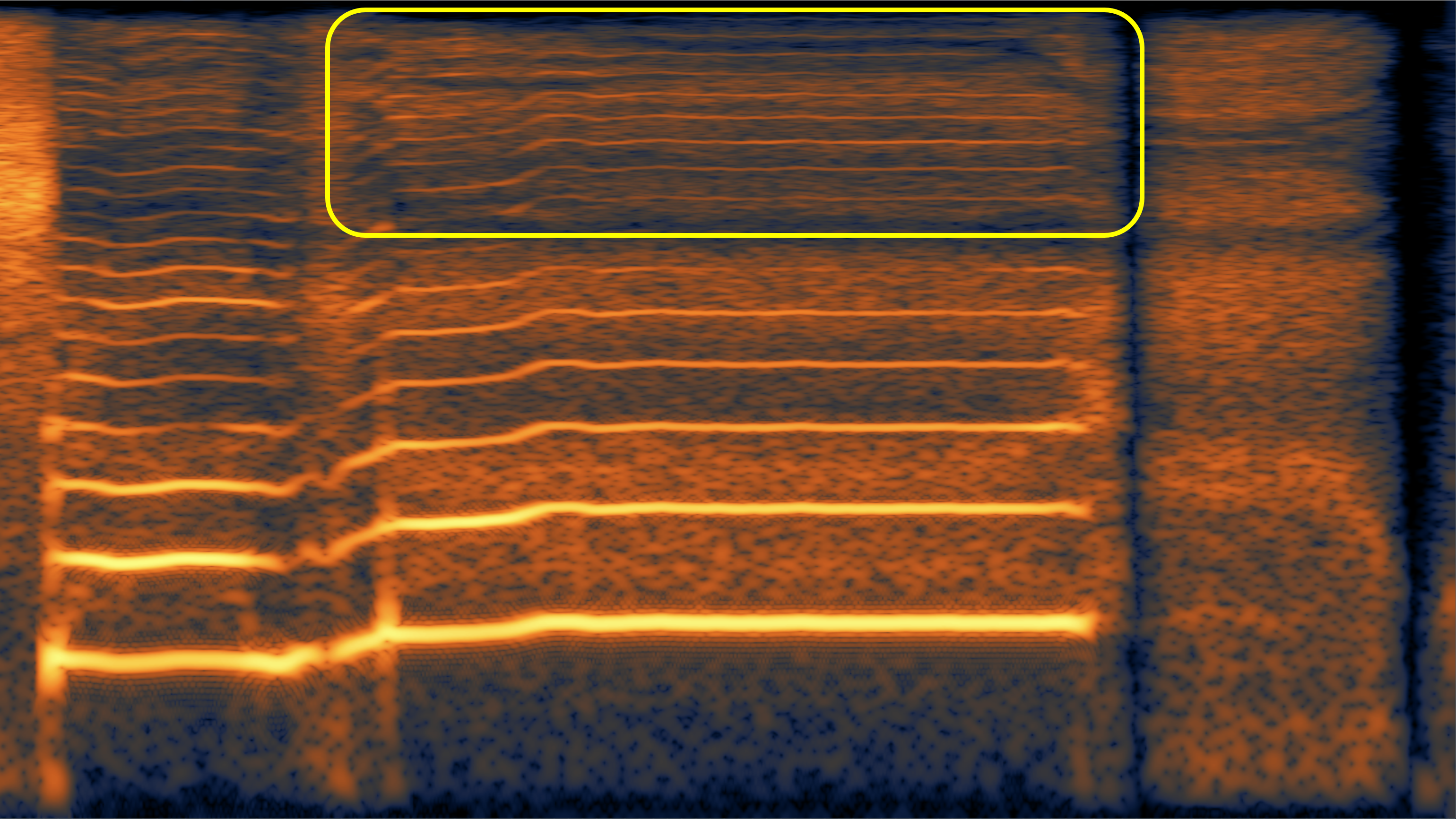
|
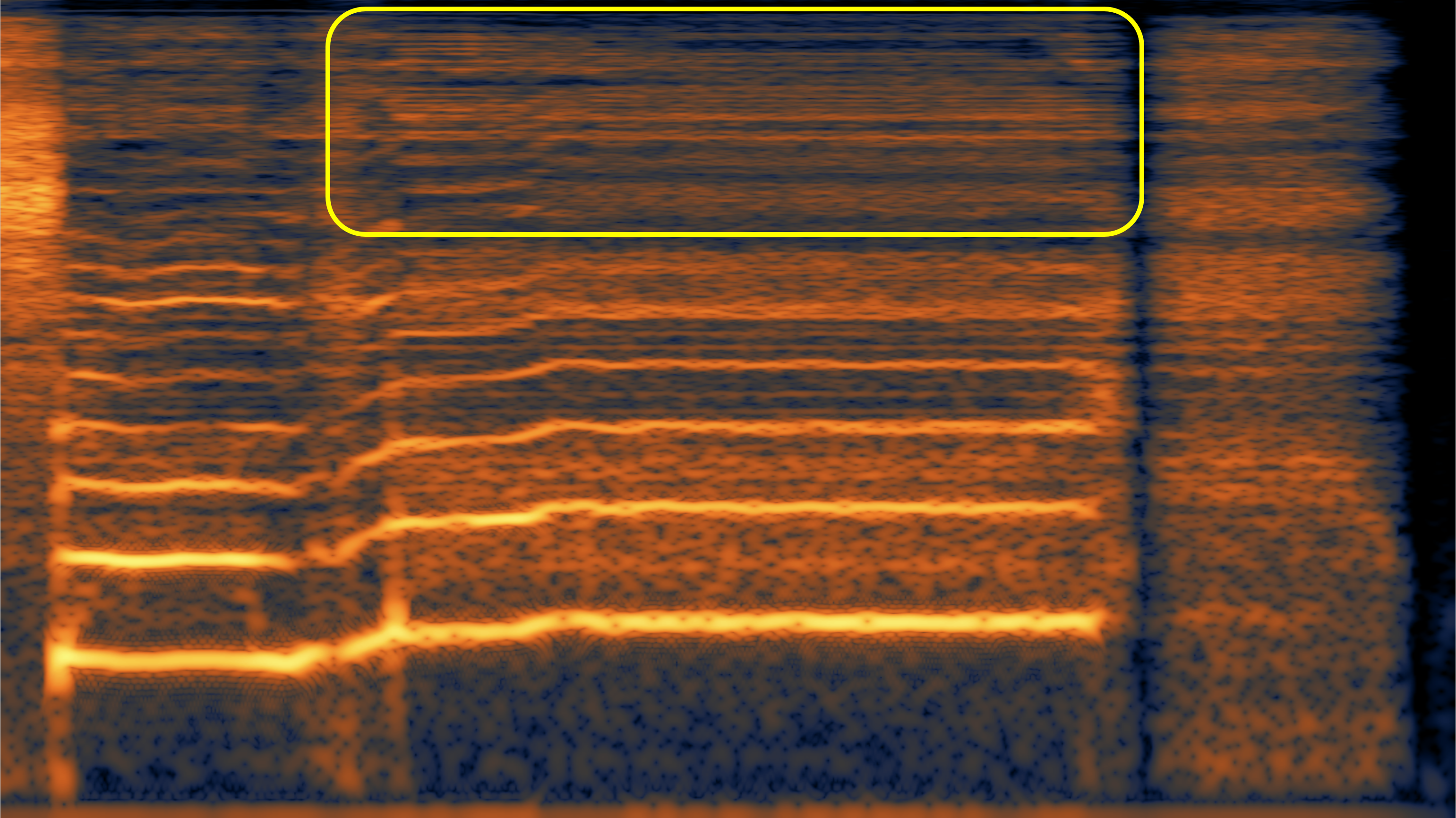
|
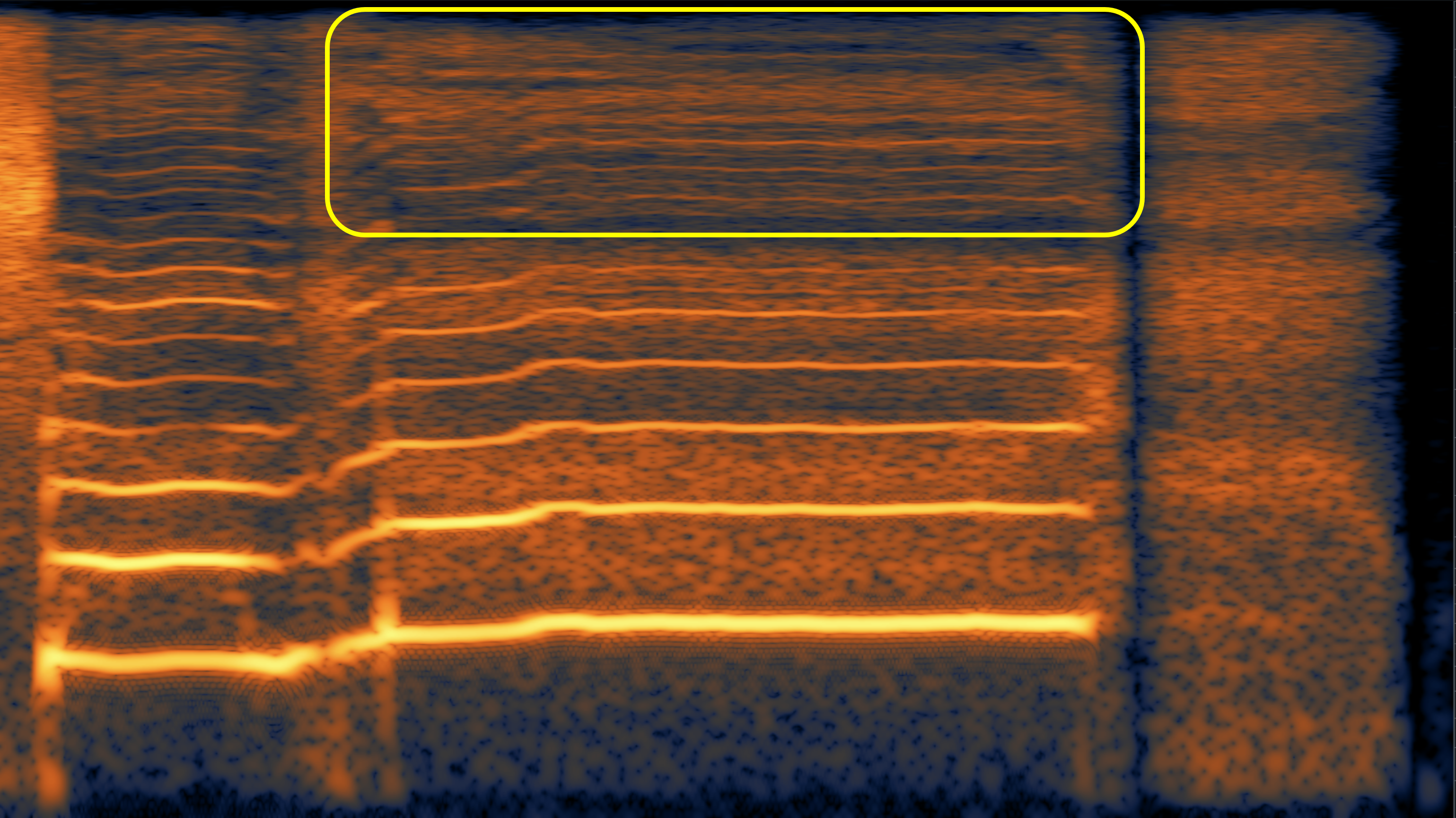
|
|
| #3 | |||
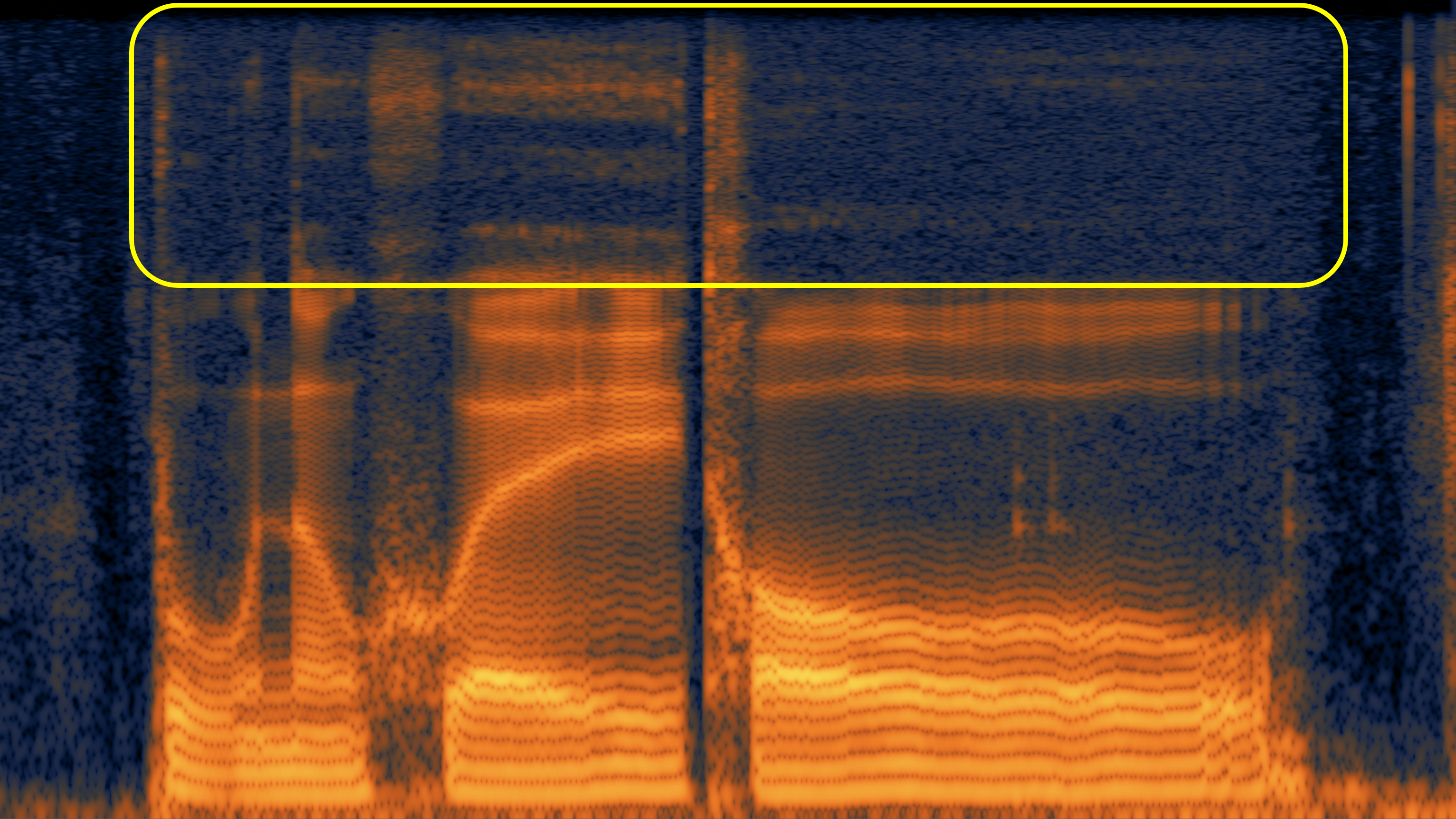
|
|
|